Cloud Computing, Docker, Continuous Delivery, BigData, Blockchain
by Walter Dal Mut, Solution Architect @ Corley.it

Walter Dal Mut



github.com/wdalmut
twitter.com/walterdalmut


https://corley.it
What is cloud computing
Summary
- On demand - self service
- Anywhere, Any time, any device
- Location independent
- Elasticity
- Pay as you go
Cloud Computing Servicesvalue visibility

On Demand
Every Cloud provider exposes API
Application programming interface
It means that you can access programmatically
to any service exposed by the provider
API means expose services

Now the light bulb has an unique HTTP address
https://somewhere.someprovider.com/bulb/198357
Our service expose a way to work with that light bulb
- Turn it on
POST /bulb/198357 {"state": "high"} - Turn it off
POST /bulb/198357 {"state": "low"} - Get current state
GET /bulb/198357 return {"state": "high|low"}
Anybody can develop applications!
- Turn it on/off at sunrise or sunset
- Emulate people presence in an house(useful when we leave on vacation)
- On alarms to turn it on/off
- There are so many possibilities...
So we can decouple our system to different and reusable parts
Reusable parts means cost saving
APIs immediately creates a new building block for any application
Now we can create our service oriented infrastructure

Pay as you go
Focus on scalability of you applications
Scalability

Scalability (Spike)

Scalability (daily hours)

Provisioning Hardware (o VM)

Real Usage

Money waste

Autoscaling environments
SOA - Service Oriented Architecture

Autoscaling - Price

Serverless
Pay for "Actual Demand"
Serverless
- No server to manage
- Scale on real usage instantaneously
- High Availability
- Pay only for single requests
Serverless + Api Gateway

Serverless beyond computing
- S3 - Simple Storage Service
- SES - Simple Email Service
- AWS Cognito
- STS - Security Token Service
- CloudFront
- API Gateway/Lambda/DynamoDB
- AWS WAF - Web Application Firewall
- AWS CloudTrail
- AWS CloudWatch
- AWS CodeDeploy
- AWS CodeBuild
- AWS CodeCommit
- Route53
- Kinesis
- ...
Pricing example
5 milioni * 3,50 USD/milione = 17,50 USD
3 KB * 5 milioni = 15 milioni KB = 14,3 GB
14,3 GB * 0,09 USD = 1,29 USD
17,50 USD + 1,29 USD = 18,79 USD
0 requests => ~0 USD
Scalability Summary
- Scale capacity on demand
- Turn fixed costs into variable costs
- Always available
- Rock-solid reliability
- Cost-Effective
- Reduce time to market
Monolith

Problems
- Difficult to scale
- Long development cycles (dev, build, test)
- So many modules (operations nightmare - who is the owner?)
- Architecture legacy (hard to maintain and evolve)
- Add features are difficult for developers
- Feature delivery can be really slow
It means...
- Lack of agility
- Lack of innovation
- Frustrated customers
Services to Micro Services
Composing and collecting APIs create a new business model where an application is decoupled into many tiny little services
What is a microservice
service-oriented architecture composed of loosely coupled elements that have bounded contexts
Adrian Cockcroft @ Netflix
Create many tiny services
Instead doing one thing

Do one thing, and do it well

Microservices achievements
- We can scale the development team
- Easy deployments (much more deployments)
- Reduce infrastructure costs
Delivery/Deployment...
hundreds of teams x
thousands of services x
different environments x
deployment time = ?
If we take 1 hour to manually build/test/deploy
100 teams x
1000 services x
3 environments x
1 hour
300000 hours for deployments12500 days for deployments37500 business days
Continuous delivery/deployment
Delivery automation

If we have 300000 deploy per year
our delivery pipeline must deploy every
30 seconds
AWS CodeBuild/CodePipeline

Measure is the key to science
Now we have tiny little services and
we can deploy those services easily
How we can save resources and deploy more applications in consolidated environment?
Instance resources

More applications?

resource contention
In computer science, resource contention is a conflict over access to a shared resource such as random access memory, disk storage, cache memory, internal buses or external network devices.
Containers
Lightweight, isolated environment for applications
CAP - Limits for resources (CPU, Memory, Networking)
It is like a sort of virtual machine but it is not!

if with virtual machine we can run up to 15/20 instances per phisical hardware, now with containers we can spawn hundres if not thousands of application per phisical hardware
Distributed architectures

Clusters for web applications
Microservices

More instances, more resources

More instances, more resources

Api gateway for applications

We have this sort of super computer where we can run our applications
Kubernetes & Docker Swarm
Orchestrators for Containers
Export control with Cloud & On-Prem federation

Many isolated but somehow connected clusters for appplications

Big Data
Big data is a collection of data sets
- so large and complex
- difficult to process
Big Data Challenges
- Capture
- Storage
- Search
- Share
- Transfer
- Analysis
- Visualization
Common Scenario
- Data arriving at fast rate
- Data are typically unstructured or partially structured
- Data are stored without any kind of aggregation
Data Grow
- Scalable storage
- In 2010 Facebook claimed that they had 21 PB of storage
- 30 PB in 2011
- 100 PB in 2012
- 500 PB in 2013
- In 2010 Facebook claimed that they had 21 PB of storage
Massive Parallel Processing
In 2012 anybody can elaborate exabytes (10^18 bytes) of data in a reasonable amount of time
Reasonable Cost (Cloud Computing)
The New York Times used 100 Amazon EC2 instances and an Hadoop application to process 4TB of raw images into 11 million finished PDFs in the space of 24 hours at a computation costs of about $240
Big Data examples
- So many data (petabyte of information)
- So many different not aggregated data sources
- ...
Petabyte of information
We cannot create a terabyte large index of our data (doesn't fit our memory)
It means that we hit a phisical limit for traditional tecnologies (Relational Databases)
Different/Not Aggregated data sources
We cannot join not structured data and from different data sources
How we can join information in our service oriented infrastructure?
We can solve those computing problems introducting a way to analyse datasets
Map/Reduce
Map
A mapping is a transformation from one value to another value
[1,2,3].map(multiplyBy3) => [3,6,9]
For example, if you start with the number 2 and you multiply it by 3, you have mapped it to 6.
Reduce
This operator combines mapped values down to the final resultset
[1,2,3]
.map(multiplyBy3) // [3,6,9]
.reduce(sum) => 18

Extend to parallel computing

Map/Reduce is an highly scalable data processing algorithm
it is all about brute force
Hadoop is a framework for distributed map/reduce
Thanks to Hadoop ecosystem we can use higher level tools to analyze/visualize etc... our data
Apache Hive
Run SQL statements over our distributed data source
Well-Known SQL statements
SELECT * FROM tickets t WHERE t.weekday = 12;
SELECT * FROM tickets t GROUP BY weekday;
SELECT * FROM tickets t JOIN users u ON (t.owner_id = u.id) WHERE u.id = 12
etc...
Blockchain
Blockchain and not Bitcoins
Bitcoins are just an application of a blockchain but it can help us to focus on different things about blockchains
Ledger
| User | Balance |
|---|---|
| Walter | 12.3 |
| Giovanni | 1.7 |
| Michele | 1.9 |
| Paola | 19.3 |
| Michela | 21.5 |
How maintains the ledger?
Central authorities in general: banks, etc.
Why we want to drop central authorities?
Transparency on transaction/tracking
...
So drop central authorities
Drop the central authorities
Walter
| User | Balance |
|---|---|
| Walter | 12.3 |
| Giovanni | 1.7 |
| Michele | 1.9 |
| Paola | 19.3 |
| Michela | 21.5 |
Paola
| User | Balance |
|---|---|
| Walter | 12.3 |
| Giovanni | 1.7 |
| Michele | 1.9 |
| Paola | 19.3 |
| Michela | 21.5 |
Giovanni
| User | Balance |
|---|---|
| Walter | 12.3 |
| Giovanni | 1.7 |
| Michele | 1.9 |
| Paola | 19.3 |
| Michela | 21.5 |
Do we spot how many problems do we have now?
- Privacy problems
- Fraud transactions
- stale/not updated ledger
- ...
Privacy problem
Walter
| User | Balance |
|---|---|
| 123432 | 12.3 |
| 143524 | 1.7 |
| 534653 | 1.9 |
| 356346 | 19.3 |
| 498647 | 21.5 |
Paola
| User | Balance |
|---|---|
| 123432 | 12.3 |
| 143524 | 1.7 |
| 534653 | 1.9 |
| 356346 | 19.3 |
| 498647 | 21.5 |
Giovanni
| User | Balance |
|---|---|
| 123432 | 12.3 |
| 143524 | 1.7 |
| 534653 | 1.9 |
| 356346 | 19.3 |
| 498647 | 21.5 |
Otherwise everybody knows my balance
How we can solve other problems if everybody has complete access to the ledger?
The way that blockchain uses to provide security is
TRUST NOBODY
Blockchain provide mathematical and crypto challenges to achieve that results and protect itself
How to maintain the DISTRIBUTED ledger?
Blockchain do not store a computed ledger but transactions

Transaction wrap an information
Transactions
- From: 12058872352
- To: 39856829385
- Amount: 2
The ledger is just a concatenation of transaction
Transactions
- From: 12058872352
- To: 39856829385
- Amount: 2
Transactions
- From: 39857312434
- To: 19385738532
- Amount: 1.5
Transactions
- From: 98357389332
- To: 39573847838
- Amount: 0.2
why is blockchain and not transaction chain?
because transactions are groupped into blocks
(of transactions of course)
Block
- Transaction 1
- Transaction 2
- Transaction 3
Blocks are linked together to create the chain
Here the blockchain
Block
- Transaction 1
- Transaction 2
- Transaction 3
Block
- Transaction 4
- Transaction 5
- Transaction 6
Block
- Transaction 7
- Transaction 8
- Transaction 9
How we could prevent data modification of a block?
How we could prevent that anybody send fraud trasactions?
With asymmetric cryptography
Digital Signature
Public Key + Private Key

- Only the private key can sign a transaction/block
- Everybody can verify a signature of a transaction/block with the public key
Digital Signature
Block
- Transaction 1
- Transaction 2
- Transaction 3
- footprint (hash)
- Signature
We cannot corrupt a block (transactions)
How to link blocks together?
Every block has also a previous hash
Block
- hash: 1234567
- previous_hash: 46754736
- signature: 13564309683405
Block
- hash: 3456789
- previous_hash: 1234567
- signature: 23895732989535
Block
- hash: 94827523
- previous_hash: 3456789
- signature: 13985723985793
So we cannot rewire the chain
Who introduce new blocks in a distributed network?
Everybody try to create blocks
The first one that creates a new block in the network is the winner
To win a reward and create a new block for the chain everyone in the network has to solve a complex mathematical problem
Proof of work
Solve a mathematical problem
Hash function of something start with `n` zeros
sha256(1404) = 000ebec3ecebd727ce4f020441268ad34ac468cdb1c76ced442380b5ac842b7d
Complex enough to take 10 minutes to solve the problem (bitcoins)
So everybody try to "mine" a new block...
What happend if two actors compute a valid block at the same time?
This is a real problem because we can have a big issue!
Double Spending Problem
Longest chain always win
Double spending on the latest block
wait 6 blocks ahead yours to have a strong confirmation of your transactions
Orphans and blockchain
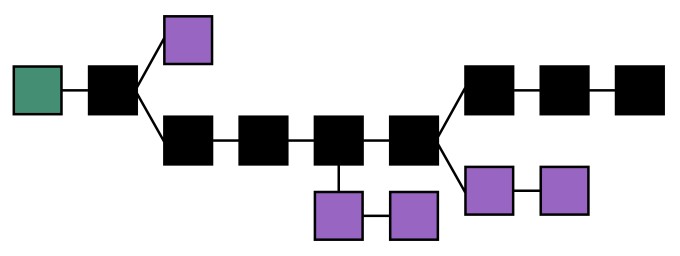
The chain must be continuously incremented to provide stability
Empty blocks or transaction filled blocks are equivalent, the point is minimize the double spending problem
But if we have to wait 6 blocks ahead our transaction to be reasonably sure about confirmation we have to wait 60 minutes (10 minutes per block generation)
Tipically we wait 2 business days to move money between bank accounts!
Private Block chain
In a private blockchain we want all features but we are not interested in rewards and proof of work in general, instead we want more speed for inserting blocks
Proof of Stake
Proof of stake is a different way to validate transactions based and achieve the distributed consensus.
The creator of a new block is chosen in a deterministic way, depending on its wealth, also defined as stake